Index
- Ideation
- Microarchitecture
- RTL Design
- Verification
- Synthesis and Place & Route
- Optimizations
- Results
Ideation
The main goal of the project is to design a scalable macro that can be used for accelerating convolution computations. This would prove useful for running inference on the edge requiring convolution compute at the best Power, Performance and Area.
The compute in convolutions are inherently are very repetitive and would be excellent candidates for SIMT machines. The goal here is to build a super efficient SIMT machine optimized for convolution.
Microarchitecture
Convolution Cell:
- The compute is to distributed across several processing elements called convolution cells.
- The convolution cell is essentially a MAC Unit and each convolution cell will perform 8 MAC operations to compute the result.
- It will only handle integer compute.
- For the sake of the class, it will operate on 8 bit inputs. The Input and Kernel will be 3x3.
Convolution Matrix:
- An array of Convolution Cells form a matrix.
- The routing is handled in this level
- Fixed routing between the convolution cells, memory and I/O
Memory:
- SRAM for fast access
RTL Design
Convolution Cell:
- Parameterize the inputs so it is scalable
- Use fast multiplier and adder from Synopsys Design Ware
- Can be further improved by implementing latency insensitive handshaking and FSM for I/O
module convolution_cell #(
parameter kernelSize = 9; //Represents the size of the kernel
parameter inputWidth = 8; //Represents the no. of bits in each pixel
)
(
input clk_i,
input reset_i,
input [inputWidth-1:0] pixel_i[kernelSize-1:0],
input signed [inputWidth-1:0] kernel_i[kernelSize-1:0],
output logic [inputWidth-1:0] pixel_o
);
logic signed [15:0] int_result[kernelSize-1:0];
logic [15:0] sum_result[(kernelSize-1)/2:0];
logic [inputWidth-1:0] cell_result;
logic sign;
logic [inputWidth-1:0] pixel[kernelSize-1:0];
logic signed [inputWidth-1:0] kernel[kernelSize-1:0];
assign sign = 1'b1;
generate
genvar i;
for (i=0;i<kernelSize;i++) begin
mult #(.A_width(kernelSize-1), .B_width(kernelSize-1)) multiplier(
.inA(pixel[i]),
.inB(kernel[i]),
.inTC(sign),
.outPRODUCT(int_result[i])
);
end
for (i=0;i<kernelSize;i++) begin
adder #(.A_width(kernelSize-1), .B_width(kernelSize-1)) summer(
.inA(int_result[2*i]),
.inB(int_result[2*i+1]),
.inTC(sign),
.outSUM(sum_result[i])
);
end
endgenerate
always_ff @(posedge clk_i)
begin
if(reset_i)
begin
cell_result <= 8'b0;
end
else
// Needs to be implemented as a FSM if multi-cycle path is involved in multiplication
begin
pixel <= pixel_i;
kernel <= kernel_i;
cell_result <= sum_result;
end
end
assign pixel_o = cell_result[7:0];
endmodule
SRAM:
- Generated using the OpenRAM project
- Decided to use 1R1W to exploit parallelism
module sram_8_16_freepdk45(
`ifdef USE_POWER_PINS
vdd,
gnd,
`endif
// Port 0: W
clk0,csb0,addr0,din0,
// Port 1: R
clk1,csb1,addr1,dout1
);
parameter DATA_WIDTH = 8 ;
parameter ADDR_WIDTH = 4 ;
parameter RAM_DEPTH = 1 << ADDR_WIDTH;
// FIXME: This delay is arbitrary.
parameter DELAY = 3 ;
parameter VERBOSE = 1 ; //Set to 0 to only display warnings
parameter T_HOLD = 1 ; //Delay to hold dout value after posedge. Value is arbitrary
`ifdef USE_POWER_PINS
inout vdd;
inout gnd;
`endif
input clk0; // clock
input csb0; // active low chip select
input [ADDR_WIDTH-1:0] addr0;
input [DATA_WIDTH-1:0] din0;
input clk1; // clock
input csb1; // active low chip select
input [ADDR_WIDTH-1:0] addr1;
output [DATA_WIDTH-1:0] dout1;
reg [DATA_WIDTH-1:0] mem [0:RAM_DEPTH-1];
reg csb0_reg;
reg [ADDR_WIDTH-1:0] addr0_reg;
reg [DATA_WIDTH-1:0] din0_reg;
// All inputs are registers
always @(posedge clk0)
begin
csb0_reg = csb0;
addr0_reg = addr0;
din0_reg = din0;
if ( !csb0_reg && VERBOSE )
$display($time," Writing %m addr0=%b din0=%b",addr0_reg,din0_reg);
end
reg csb1_reg;
reg [ADDR_WIDTH-1:0] addr1_reg;
reg [DATA_WIDTH-1:0] dout1;
// All inputs are registers
always @(posedge clk1)
begin
csb1_reg = csb1;
addr1_reg = addr1;
if (!csb0 && !csb1 && (addr0 == addr1))
$display($time," WARNING: Writing and reading addr0=%b and addr1=%b simultaneously!",addr0,addr1);
#(T_HOLD) dout1 = 8'bx;
if ( !csb1_reg && VERBOSE )
$display($time," Reading %m addr1=%b dout1=%b",addr1_reg,mem[addr1_reg]);
end
// Memory Write Block Port 0
// Write Operation : When web0 = 0, csb0 = 0
always @ (negedge clk0)
begin : MEM_WRITE0
if (!csb0_reg) begin
mem[addr0_reg][7:0] = din0_reg[7:0];
end
end
// Memory Read Block Port 1
// Read Operation : When web1 = 1, csb1 = 0
always @ (negedge clk1)
begin : MEM_READ1
if (!csb1_reg)
dout1 <= #(DELAY) mem[addr1_reg];
end
endmodule
Convolution Matrix:
- Implemented latency insensitive handshaking to handle data input and output.
- Implemented a 5 state FSM - Input, Wait, Busy, Done, Output
- Input state fetches all the input data. For a coloured image, this could take upto 3 clock cycles. One cycle each for Red, Green, Blue values.
- Wait state drives the control signals for the Convolution Cell and SRAM
- Busy state - The convolution cell handles compute
- Done state - Write-back of the result happens to memory
- Repeated States - Wait, Busy and Done loop for 2 more times to calculate Green and Blue results as well
- Output state - The matrix outputs the result of the convolution
Verification
Convolution Cell:
- Unit testing using directed testbenches
- Analyzed waveforms on Verdi to confirm working of the module
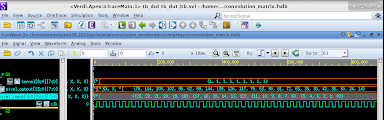
Convolution Matrix:
- Generated automated testbenches from a python script
- The script reads an input image. Generates traces to be provided as inputs.
- The script also calculates convolutions. Generates traces to be compared as outputs.
- The output from the accelerator should match the output trace from the script.
- The script automatically compares the results and prints whether it matched on the terminal.
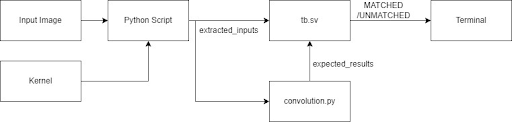
Core of Python Script:
im = Image.open('input.jpg')
pix = im.load()
width, height = im.size
iterations = int(width/6)
width_steps = width/iterations
height_steps = height/iterations
def convolution_calc(image_i,kernel, width, height):
result = np.zeros((width+2, height+2), dtype = np.int_)
for a in range(width):
for b in range(height):
result[a+1][b+1] = image_i[a][b]
for a in range(width):
for b in range(height):
image_i[a][b] = result[a][b]*kernel[0][0] + result[a + 1][b]*kernel[1][0] + result[a + 2][b]*kernel[2][0] + result[a][b+1]*kernel[0][1] + result[a + 1][b + 1]*kernel[1][1] + result[a + 2][b + 1]*kernel[2][1] + result[a][b+2]*kernel[0][2] + result[a + 1][b+2]*kernel[1][2] + result[a + 2][b + 2]*kernel[2][2]
return image_i
for y in range(height):
for x in range(width):
red[x][y], green[x][y], blue[x][y] = pix[x,y]
for y in range(4):
for x in range(6):
input_pix_red[x][y] = int(red[x][y]/div_fact)
input_pix_green[x][y] = int(green[x][y]/div_fact)
input_pix_blue[x][y] = int(blue[x][y]/div_fact)
convolution_result_red = convolution.convolution_calc(input_pix_red,kernel,6,4)
convolution_result_green = convolution.convolution_calc(input_pix_green,kernel,6,4)
convolution_result_blue = convolution.convolution_calc(input_pix_blue,kernel,6,4)
Minimal testbench generated by the python script:
module tb_dut (
);
logic clk, valid_i, valid_o, ready, ready_i, reset;
logic [71:0]kernel;
logic [191:0] pixel_output;
logic [191:0] pixel_input;
logic [191:0] red_output, green_output, blue_output;
integer i,j;
logic [3:0] addr;
logic red_matched, green_matched, blue_matched;
convolution_matrix conv(
.clk_i(clk),
.v_i(valid_i),
.yumi_i(ready_i),
.reset_i(reset),
.kernel_i(kernel),
.addr_i(addr),
.ready_o(ready),
.v_o(valid_o),
.pixel_o(pixel_output),
.pixel_i(pixel_input)
);
initial begin
clk <= 0;
forever #(100) clk <= ~clk;
end
initial begin
`ifndef PRE_SYN
$sdf_annotate("convolution_matrix.sdf", conv);
`endif
$fsdbDumpfile("convolution_matrix.fsdb");
$fsdbDumpvars();
$dumpfile("convolution_matrix.vcd");
$dumpvars();
end
initial begin
valid_i = 0;
ready_i = 0;
reset = 1;
kernel = 0;
addr = 0;
pixel_input = 0;
#200 reset = 0;
end
initial begin
#200
valid_i=1;
addr = 0;
reset=0;
kernel= 72'b_00000000_00000000_00000000_00000000_00000001_00000000_00000000_00000000_00000000;
pixel_input = 192'b_11100100_11100010_11011101_11011000_11010001_11000111_11100100_11100010_11011101_11011000_11010001_11000111_11100100_11100010_11011101_11011000_11010010_11000111_11100011_11100010_11011110_11011001_11010010_11000111;
#200
addr = 1;
pixel_input = 192'b_10111100_10111010_10110110_10110001_10101010_10100010_10111100_10111001_10110110_10110001_10101010_10100010_10111011_10111001_10110110_10110001_10101011_10100010_10111010_10111001_10110111_10110010_10101011_10100010;
addr = 2;
pixel_input = 192'b_10011001_10010111_10010101_10010010_10001011_10000101_10011001_10011001_10010101_10010010_10001011_10000101_10011011_10011001_10010101_10010010_10001110_10000101_10011010_10011001_10011000_10010011_10001110_10000111;
#200
valid_i = 1;
#9000
red_output = pixel_output;
addr = 0;
#9200
addr = 1;
green_output = pixel_output;
#9400
addr = 2;
blue_output = pixel_output;
#10000
$display("#########################PRINTING RESULTS######################");
if(red_matched)
$display("RED MATCHED");
else
$display("RED UNMATCHED");
if(green_matched)
$display("GREEN MATCHED");
else
$display("GREEN UNMATCHED");
if(blue_matched)
$display("BLUE MATCHED");
else
$display("BLUE UNMATCHED");
$display("###########################COMPLETED#######################");
$finish;
end
always_comb begin
if(valid_o) begin
if(addr == 0) begin
if(pixel_output == 192'b_11100100_11100010_11011101_11011000_11010001_11000111_11100100_11100010_11011101_11011000_11010001_11000111_11100100_11100010_11011101_11011000_11010010_11000111_11100011_11100010_11011110_11011001_11010010_11000111)
begin red_matched = 1; end
else
begin red_matched = 0; end
end
if(addr == 1) begin
if(pixel_output == 192'b_10111100_10111010_10110110_10110001_10101010_10100010_10111100_10111001_10110110_10110001_10101010_10100010_10111011_10111001_10110110_10110001_10101011_10100010_10111010_10111001_10110111_10110010_10101011_10100010)
begin green_matched = 1; end
else
begin green_matched = 0; end
end
if(addr == 2) begin
if(pixel_output == 192'b_10011001_10010111_10010101_10010010_10001011_10000101_10011001_10011001_10010101_10010010_10001011_10000101_10011011_10011001_10010101_10010010_10001110_10000101_10011010_10011001_10011000_10010011_10001110_10000111)
begin blue_matched = 1; end
else
begin blue_matched = 0; end
end
end
end
endmodule
Synthesis and APR
- Used Synopsys Design Compiler for Synthesis on FreePDK45
- Used Synopsys IC Compiler for Automatic Place and Route Layout
- Created TCL scripts for synthesis, floorplanning, apr
- Created a hardmacro of the Convolution Cell
Script for Static Timing Analysis:
# Get configuration settings
source ../../src/syn/config.tcl
# Clocks
# =====================================
create_clock -name "clk" \
-period "$CLK_PERIOD" \
-waveform "0 [expr $CLK_PERIOD/2]" \
[get_ports $CLK_PORT]
# create_clock -name "clk" \
# -period "$CLK_PERIOD" \
# -waveform "0 [expr $CLK_PERIOD/2]" \
# [get_pins i_root_clk_gater/gclk]
#High fanout net
set_ideal_network [get_net reset_i] -no_propagate
# global margin
set_critical_range $clk_critical_range $current_design
# uncertainty
set_clock_uncertainty -setup ${clk_setup_uncertainty} "clk"
set_clock_uncertainty -hold ${clk_hold_uncertainty} "clk"
# transition
set_clock_transition ${clk_trans} [get_clocks]
set_fix_hold [get_clocks]
# Fanout, transition,
# ==============================================
set_max_fanout $max_fanout $current_design
set_max_transition $max_trans $current_design
##############################################################################
# #
# TIMING DERATE AND RECONVERGENCE PESSIMISM REMOVAL #
# #
##############################################################################
# Set setup/hold derating factors. 20%.
# -clk ensures application of derate only to clk paths.
# This will be applied to both setup and hold paths (see definition of set_timing_derate)
# If you want the part to really not end up faster than you built it for, will likely have to relax cycle time.
set_timing_derate -early 0.8
set_timing_derate -late 1.0
#Avoid tracking entire early and late paths altogether. That is excessive. Remove that pessimism.
set timing_remove_clock_reconvergence_pessimism true
# Path groups
# ==============================================
group_path -name "Inputs" -from [remove_from_collection [all_inputs] [get_ports $CLK_PORT]]
group_path -name "Outputs" -to [all_outputs]
group_path -name "Feedthroughs" -from [remove_from_collection [all_inputs] [get_ports $CLK_PORT]] \
-to [all_outputs]
group_path -name "Regs_to_Regs" -from [all_registers] -to [all_registers]
# Boundary timing/loading
# ==============================================
# outputs
set_output_delay $blanket_output_delay -clock "clk" [all_outputs]
set_load [load_of $blanket_input_load] [all_outputs]
# inputs
set_input_delay $blanket_input_delay -clock "clk" \
[remove_from_collection [all_inputs] [get_ports $CLK_PORT]]
set_drive [drive_of $blanket_output_drive] [all_inputs]
# Operating conditions
# ==============================================
set_operating_conditions -max $LIB_WC_OPCON -max_library $LIB_WC_NAME \
-min $LIB_BC_OPCON -min_library $LIB_BC_NAME
Script of creating a Hard Macro of Convolution Cell:
source ../../src/syn/synMacro.tcl //Synthesizes the RTL
source ../../src/syn/configMacro.tcl //Contains config parameters for the process-node, sta
source ../../src/syn/libraryMacro.tcl //Contains list of libraries that are to be imported
set design_name "convolution_cell"
read_verilog ./results/$design_name.syn.v
read_sdf ./results/$design_name.syn.sdf
read_parasitics -format SPEF ./results/$design_name.syn.spef
extract_model -output cc_macro
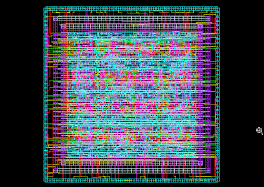
Core of the floorplanning script:
#### SET FLOORPLAN VARIABLES ######
set CELL_HEIGHT 1.4
set CORE_WIDTH_IN_CELL_HEIGHTS 545
set CORE_HEIGHT_IN_CELL_HEIGHTS 410
set POWER_RING_CHANNEL_WIDTH [expr 10*$CELL_HEIGHT]
set CORE_WIDTH [expr $CORE_WIDTH_IN_CELL_HEIGHTS * $CELL_HEIGHT]
set CORE_HEIGHT [expr $CORE_HEIGHT_IN_CELL_HEIGHTS * $CELL_HEIGHT]
create_floorplan -control_type width_and_height \
-core_width $CORE_WIDTH \
-core_height $CORE_HEIGHT \
-core_aspect_ratio 1.50 \
-left_io2core $POWER_RING_CHANNEL_WIDTH \
-right_io2core $POWER_RING_CHANNEL_WIDTH \
-top_io2core $POWER_RING_CHANNEL_WIDTH \
-bottom_io2core $POWER_RING_CHANNEL_WIDTH \
-flip_first_row
# Power straps are not created on the very top and bottom edges of the core, so to
# prevent cells (especially filler) from being placed there, later to create LVS
# errors, remove all the rows and then re-add them with offsets
cut_row -all
add_row \
-within [get_attribute [get_core_area] bbox] \
-top_offset $CELL_HEIGHT \
-bottom_offset $CELL_HEIGHT
#-flip_first_row \
### ADD STUFF HERE FOR THE MACRO PLACEMENT.
##### PLACING YOUR RAM AND DERIVING CELL INFO######
#cell0
set CELL_0 "genblk1_0__cells"
# Get height and width of cell
set CELL_0_HEIGHT [get_attribute $CELL_0 height]
set CELL_0_WIDTH [get_attribute $CELL_0 width]
# Set Origin of CELL
set CELL_0_LLX [expr 30*$CELL_HEIGHT]
set CELL_0_LLY [expr 30*$CELL_HEIGHT]
# Derive URX and URY corner for placement blockage. "Width" and "Height" are along wrong axes because we rotated the CELL.
set CELL_0_URX [expr $CELL_0_LLX + $CELL_0_HEIGHT]
set CELL_0_URY [expr $CELL_0_LLY + $CELL_0_WIDTH]
set GUARD_SPACING [expr 2*$CELL_HEIGHT]
set_attribute $CELL_0 orientation "E"
set_cell_location \
-coordinates [list [expr $CELL_0_LLX ] [expr $CELL_0_LLY]] \
-fixed \
$CELL_0
# Create blockage for filler-cell placement.
create_placement_blockage \
-bbox [list [expr $CELL_0_LLX - $GUARD_SPACING] [expr $CELL_0_LLY - $GUARD_SPACING] \
[expr $CELL_0_URX + $GUARD_SPACING] [expr $CELL_0_URY + $GUARD_SPACING]] \
-type hard
# Connect RAM power to power grid
connect_net VDD [get_pins -all genblk1_0__cells/vdd]
connect_net VSS [get_pins -all genblk1_0__cells/gnd]
## end of cell0 ##
set RAM_0 "genblk1_0__ram"
# Get height and width of RAM
set RAM_0_HEIGHT [get_attribute $RAM_0 height]
set RAM_0_WIDTH [get_attribute $RAM_0 width]
# Set Origin of RAM
set RAM_0_LLX [expr 95*$CELL_HEIGHT]
set RAM_0_LLY [expr 30*$CELL_HEIGHT]
# Derive URX and URY corner for placement blockage. "Width" and "Height" are along wrong axes because we rotated the RAM.
set RAM_0_URX [expr $RAM_0_LLX + $RAM_0_HEIGHT]
set RAM_0_URY [expr $RAM_0_LLY + $RAM_0_WIDTH]
set GUARD_SPACING [expr 2*$CELL_HEIGHT]
set_attribute $RAM_0 orientation "E"
set_cell_location \
-coordinates [list [expr $RAM_0_LLX ] [expr $RAM_0_LLY]] \
-fixed \
$RAM_0
# Create blockage for filler-cell placement.
create_placement_blockage \
-bbox [list [expr $RAM_0_LLX - $GUARD_SPACING] [expr $RAM_0_LLY - $GUARD_SPACING] \
[expr $RAM_0_URX + $GUARD_SPACING] [expr $RAM_0_URY + $GUARD_SPACING]] \
-type hard
# Connect RAM power to power grid
connect_net VDD [get_pins -all genblk1_0__ram/vdd]
connect_net VSS [get_pins -all genblk1_0__ram/gnd]

Optimizations
Performance Optimization: Banking
-
Broke down a SRAM of size > 16KB into multiple small banks.
-
Each bank is associated with one convolution cell. Each bank has a capacity of 16 words and can handle 1 read and 1 write in each cycle.
Power Optimization: Clock Gating
always_latch
begin
if (~clk_i)
begin
clk_compute_latch <= clk_compute_en;
clk_memory_latch <= clk_memory_en;
end
end
assign clk_compute = clk_i & clk_compute_latch;
assign clk_memory = clk_i & clk_memory_latch;
Area Optimization: Floorplanning
- Explored different floorplanning configurations to arrive at the best possible area.
Results
Convolution Cell:
- Critical Path - 4.83 ns
- Total Power - 238.44 uW (Dynamic Power = 195.18 + Leakage Power = 43.25) //This may not be the most recent, but the only data I have a record of.
- Area - 2891.95 um^2
Convolution Matrix
- Critical Path - 4.81 ns
- Total Power - 332.6296 uW
- Area - 847176.06 um^2